Hello SonjaX6
I think Roger has left the forum for an extended period. His last post was on 20 Sept, where he said: “I am very busy and will be taking a longer brake at this moment.” No telling when he will be back.
Hello SonjaX6
I think Roger has left the forum for an extended period. His last post was on 20 Sept, where he said: “I am very busy and will be taking a longer brake at this moment.” No telling when he will be back.
yes, let’s hope he got the boot!
If I move the shot 1 location 80m North of Crooks the error for shot 9 increases from 2.5m to 20m. The best location for shot 9 moves 106m to the South and 62m to the East.
It also increases the error for the other shots from 1.4m to 3.8m.
I think I am going to try for a solution using sources 3, 5, 6, 7 and NTD, since they at least all try to push the solution is the same direction. Since I never got sources 2 and 4 to really converge for shots 4-8, I don’t know why I would then use them for shots 1-3. I won’t be able to run it tonight but maybe in the morning.
in which message did he announce his absence?
if you look at the progress this forum has made the past week and you compare this to the previous weeks, you will be amazed…
I am really surprised how much his presence and endless debates and energy vampire activities slowed us down!
so, let’s enjoy every minute of this period!
Post 2184 of this thread, above. That is where I got the quote from.
From all I’ve heard, as well as my common sense, the detail should have hustled him off the stage ASAP.
No photo op, no shoes, just get him off asap. The damage from a cut on his foot pales in comparison to getting shot.
Of course, the fact that Trump’s personal detail allowed him to get a photo op is about number 25 to 30 in seriousness of f-ups performed that day.
And I’ll say this again: Why don’t the details have a ballistic shield handy for times like this? A secret service agent’s body is piss poor shield, after all.
By this, you do not know how a gas semi auto works.
Anyone knows why his shoes have been removed?
@sonjax6: I have a strange question which annoys me.
Math teachers say zero at 0th power does not exist. There are different limits, so there is no limit.
However, in my polynom calculation it was a good assumption that it is 1 within circumstances. So I would like to state that 0 at 0th power is just ambiguous. I will not deny its existence.
IIRC, Trump’s shoes ‘popped’ off when the US-SS dog piled him on the stage. That it was not on purpose, it just happened. That is the story I remember from the days following the attack.
It’s all just too long ago…
If I remember right, the limit of any real number to the zeroeth power as that number approaches zero is 1. You can use that limit in some derivations and applications.
There are a few paradoxes in math, but nothing in math bothered me nearly as much as the paradoxes in physics. That’s a big part of the reason I never passed the “modern physics” (AKA relativity and quantum mechanics) class in college.
I guess we should consider the calculation uncertainty.
Laplace’s demon can theoretically calculate with infinite digits of numbers.
Another thing bothers me. Is the spectrum continuous, or it has finite number of frequencies? (This is strange when you consider the energy of each frequencies.)
Additionally, there is uncertainty in wave mechanics.
For example, consider the envelope as exp(-t/T). Where is the end? Theoretically it is nowhere. This would be a never ending story. But somewere it disappears among the random fluctuations. So somewhere we lost the linear superposition at a certain level. I’m confused.
To avoid these problems, people use cookbooks.
you have to look into set theory…
in short, n^m = n to the power of m is defined as the number of mappings between a set containing n elements to a set containing m elements.
the empty set has no elements, which makes n=m=0, and there is only one mapping from the empty set to the empty set, which makes 0^0 = 1
I have no experience with firearms.
So it is technically not possible to fire blanks with an AR-15, which would be just as loud as normal ammunition?
What exactly is the reason for this?
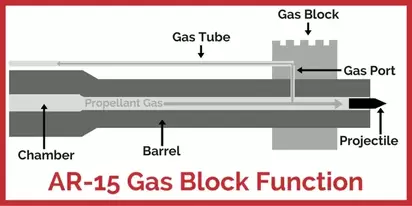
When a cartridge is fired, gas is pushing the bullet down the barrel. When the bullet passes the gas port in the barrel, some of that gas flows back to operate the system. To fire blanks in a AR type rifle, you need a blank adapter which mostly blocks the barrel and send gas thru the gas port.
5.56 blanks do not look the same as regular cartridge cases. So someone would have to pick them up and replace them with normal cases.

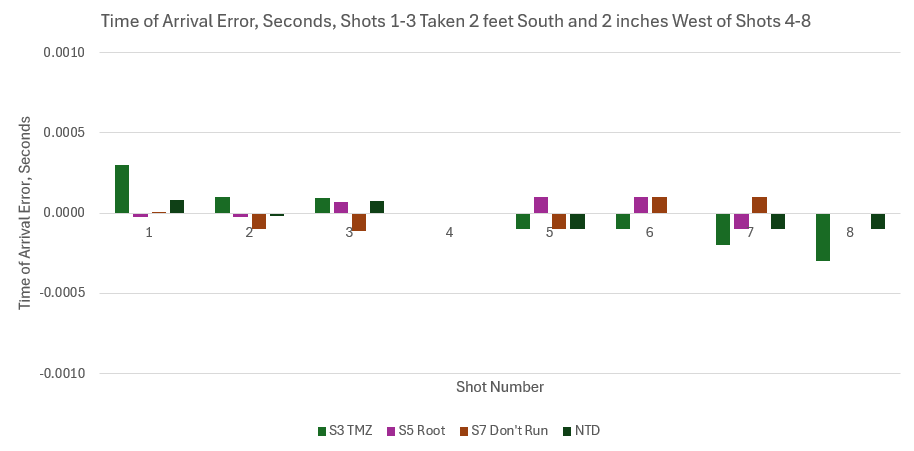
So I tried to minimize TOA errors using the podium, S3 TMZ, S5 Root, S7 Don’t Run, and NTD. These sources are basically stationary. I searched over a space where the location of shots 4-8 was fixed on Crooks and the location of shots 1-3 was a fixed offset from that, which I varied.
This is actually a decent set of sources because S3 is mostly sensitive to North-South and the others have sensitivity to East-West and North-South.
I get a really nice minima when the location of shots 1-3 is 2 feet south and 2 inches west of Crooks. Yes, inches, the minima is sharp.
The two biggest outliers are shots 1 and 8 for S3 TMZ, and they are only 4 inches off in time of arrival, so a bit of cell phone or muzzle movement could cause this. Everything else is within an inch of perfect time of arrival.
So, I am willing to accept one of two conclusions.
I’ve been away for the past two days having fun at a car club event.
Yes, there are other models, and I expect there will be some variations between models. But we only have so much data to work with, so there will be significant similarity, as well.
My model is not necessarily the “best”, and I’ve never claimed that it was. It’s just based upon what I’m comfortable with. My background is in radar signal processing, so my model performs localization based on “pulses” (gunshots) received by multiple receivers.
I published a very solid set of data and conclusions on Aug 16. At that time, I asked other analysts to pursue their own approaches and either confirm my results or challenge them. It’s taken a while for other analysts to draw conclusions, but that’s fine. This is a very complicated problem, and I totally get it. It it took me about 10x the amount of time I initially thought it would take for me to analyze the data and make conclusions. Recently, @vt1 and @offtheback have shared some results, and I appreciate the level of care they are taking to make sure their conclusions are clear and well understood. Volunteer efforts take time, and that is fine.
Shots 1-8 are not simply dependent on shots 9 & 10. It’s more accurate to say that all 10 shots are interdependent upon each other. Why? Because all 10 shots were recorded by 7+ sound recorders. So, as analysists, we can’t “change” the location of shot 9 without changing the locations for the other nine shots, as well. That’s what I mean by inter-dependency.
Unfortunately, no. We could only do that if the sound recorders were time-synched, and we had millisecond agreement between the recorders. This is impossible when multiple smartphones are used as the recording sources. We need millisecond level accuracy to determine locations, and the raw cell phone recordings don’t give us that, unless we perform additional processing.
By “processing”, I just mean that we need to assume that one of the 10 shots came from a specific location. So, that shot, at that location, is declared as “truth”, and we use that to sync all the recorders, then the other nine shots are computed.
Could it be possible to use Trump’s voice to synchronize the multiple cell phones? Unfortunately, no. Again, we need millisecond precision, and voice synch does not give us that in this case. Sound from loudspeakers recorded over a long distance is simply not clear enough to do that. It’s too “muddy”.
It is good that you are asking questions like this, @daniel59 , so please keep them coming.
Is it technically possible to produce cartridges (custom made) whose muzzle blast would be just as loud as normal ammunition, but with a subsonic bullet that would only travel 50 meters?
why do you think blanks were fired?
Corey Comperatore did not die from a blank, and I am sure that David Dutch and James Copenhaver did not get injured by a blank either…
That JCB hydraulic telehandler/lift did not get damaged by a blank either…
Not mentioning Trump intentionally.